多路复用技术
多路复用技术
参考:
- 腾讯面试:请描述 select、poll、epoll 这三种IO多路复用技术的执行原理
- 有部分笔记在《五种IO模型》里
目录
- 传统阻塞IO
- NIO
- BIO
- 多路复用
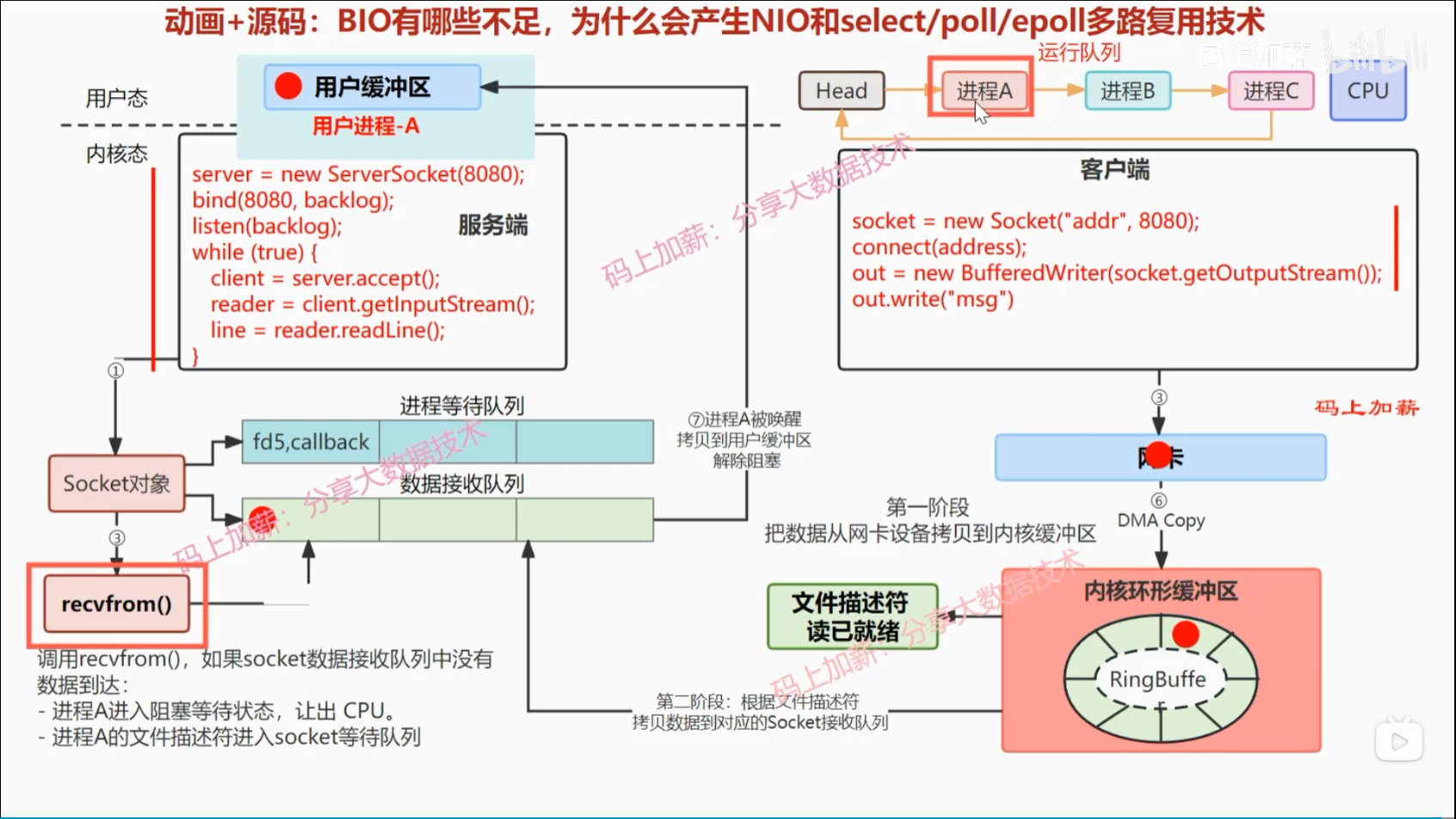
BIO底层原理与不足
动画讲解原理
Java 运行到 server.accept() 时,阻塞等待三次握手。实际上底层在内核态创建了一个socket对象,并添加到进程等待队列中
Java 运行到 reader.readLine() 时,再次阻塞,等待接收。底层是对应 recvfrom() 方法
_
接收:
第一阶段:
客户端发送数据到服务端网卡后,服务端先会通过 DMA Copy 拷贝数据到自己的内核环形缓冲区中,RingBuffer,发生IO软中断,同时文件描述符读就绪。
(DMA (直接内存访问):是发生在IO设备和主存之间的。
DMA控制器的硬件位置通常是主板上的芯片组或南桥芯片中,也可能集成在CPU上。
可以有效减少CPU切换直接将内存放入对应的主存空间,这里对应的空间则是 RingBuff)
第二阶段:
根据文件描述符拷贝数据到对应的Socket接收队列中。recvfrom在把数据从内核态复制到用户态中才会接触阻塞
图注:
四块不同的内存:
- "设备数据接收队列":网络设备,如网卡上的硬件缓冲区,用于暂存从网络上接收到的数据包。这部分内存是设备专用的,不属于主机内存。
- "内核环形缓冲区":内核空间。用于存储从设备数据接收队列拷贝过来的数据包,以供内核处理
- "内核数据接收队列":内核空间。用于存储从内核环形缓冲区中处理过的数据包,等待被用户态程序读取。这是一个FIFO(先进先出)队列
- "用户空间":用户空间。是操作系统为用户态程序分配的内存空间。当用户态程序通过系统调用读取网络数据时,数据会从内核数据接收队列拷贝到用户空间
- 补充举例:就是read(buf*) 的buf里。
- 补充等待:传统的非阻塞等待 (如事件通知),只是信息到达前不等待,但从内核接收队列/ringBuf中拷贝到用户态的过程,这个拷贝是阻塞的。
而真AIO,则是提供一个桶,在拷贝的过程都是不阻塞的(这需要系统级的支持,Linux无AIO)
(libevent 的事件通知机制,我猜测是在拷贝后才进行事件通知,但这应该只是模拟AIO而不是真AIO,应该会有拷贝阻塞发生在库里)相互关系
- 一般而言。到达网卡的数据被read(buf*)读取后,一般来说,会经历两次内存拷贝。这就是常说的 “两次拷贝”。
- 一次是从 "设备接收队列" 拷贝到 "内核环形缓存区",也叫 "DMA Copy"。并且此时会将文件描述符状态中 "未就绪" 改成 "已就绪"
- 另一次是从 "内核接收队列" 拷贝到 "用户空间"
- 你可能会发现怎么好像不对,"内核环形缓冲队列 -> 内核接收队列" 呢?
解释是:因为内核环形缓冲区和内核接收队列都处于内核空间,所以数据在这两者之间的移动通常不被视为真正意义上的“拷贝”,因为它们只是在内核内部移动,没有涉及到用户空间和内核空间之间的切换。甚至这里可能会存在通过指针或页表映射等方式实现的零拷贝。所以在这里,我们通常说数据包经历了 "两次拷贝"- 但如果使用DPDK。数据包被读取后只需要一次内存拷贝,即从设备接收队列拷贝到用户空间
操作系统层
略
NIO底层原理与不足
Java可以使用 ssC.configureBlocking(false); 将BIO转化为NIO
recvfrom发现没有数据到达 (数据接收队列为空),则会马上返回一个 -1
更准确的说法是:非阻塞 read:在数据到达网卡前,或已到达网卡但还没有拷贝到接收队列前,会立刻返回 -1
优点
- 两处阻塞变成一次阻塞。等待不阻塞,拷贝阻塞
缺点
一次阻塞
- 在从 "数据接收队列" 拷贝到 "用户空间" 这一过程,其实还是会发生阻塞。但这一阻塞是
操作阻塞而非等待阻塞,相对没那么长 - 不过Linux都是同步IO,没提供AIO (Windows倒是有),必须发生一次阻塞
- 在从 "数据接收队列" 拷贝到 "用户空间" 这一过程,其实还是会发生阻塞。但这一阻塞是
两次线程切换
- 当数据到达数据接收队列,该进程会阻塞等待读数据,发生一次线程切换,对应线程会让出cpu资源
- 数据接受拷贝到用户空间后,线程被重新唤醒,加入到进程等待队列中,再发生一次线程切换
不断轮询,浪费资源
三种多路复用技术
Select
特点:Select是最早的一款IO多路复用模型,它将所有的socket都存储在一个1024长的数组中
缺点:
每次调用Select都需要遍历整个数组,所以处理效率比较低。
其最大的缺点是每次返回结果后,用户必须遍历整个fd集合才能得到已经就绪的socket,这就是所谓的O(n)复杂度。
同时,它有最大连接数限制,即FD_SETSIZE限制,通常其值为1024。Select适用于连接数不是特别多,且连接都比较活跃的情况。
Poll和Epoll等都不存在这个问题
Poll
- 特点:设计初衷是为了克服Select模型的缺点
- 优点:
- 没有最大连接数的限制
- 返回结果后它能够直接找到就绪的socket,这是因为它记住了上次搜索的位置。
- 缺点:Poll仍然存在效率较低的问题,尤其是在处理大量空闲连接时,因为它依然需要遍历所有的连接。
Epoll
- 特点:Epoll是在2.6内核中出现的,是为了克服Select、Poll效率低下的问题。名字中的e可以理解成 extend-poll 的意思。
- 优点:
- Epoll使用一个事件驱动方式,只对发生变化的socket进行操作
- 在活动连接较少的情况下,效率会很高
- 没有最大连接数的限制,这是因为在内核中我们是根据链表来存储的(同时用了链表和红黑树,链表是就绪链表,红黑树是注册文件描述符)
- 缺点:Epoll在连接数非常多,且都非常活跃的情况下,会导致一次Epoll返回的可读事件过多,进而导致处理不过来。
IOCP
- 特点:IOCP是Windows下的一种高效IO模型,全称为I/O Completion Port,即I/O完成端口。IOCP是Windows下效率最高的异步I/O模型,它本质上是一个多线程的消息队列模型,各个线程通过GetQueuedCompletionStatus等待I/O完成消息。这些消息由系统在合适的时候为每个I/O操作送入队列,线程则负责处理I/O操作后的数据处理工作
- 优点:操作系统对线程的优秀管理能力和合理的调度机制
库使用:
- Libevent
- Linux:Libevent优先选择 epoll 作为其事件通知机制。Reactor 模型
- Windows:如果系统不支持epoll,那么Libevent会选择poll或者select。在Windows平台上,Libevent使用 select 作为事件通知机制。Reactor 模型
- Asio
- Windows:IOCP。Reactor 模型
- Linux:Asio使用 epoll 作为其事件通知机制。如果系统不支持epoll,那么Asio也可以选择使用poll或者select。
Asio同时还提供了一个 模拟的 Proactor 模式(与reactor模式相对),可以在不支持异步操作的平台上模拟异步操作,从而提供统一的API。
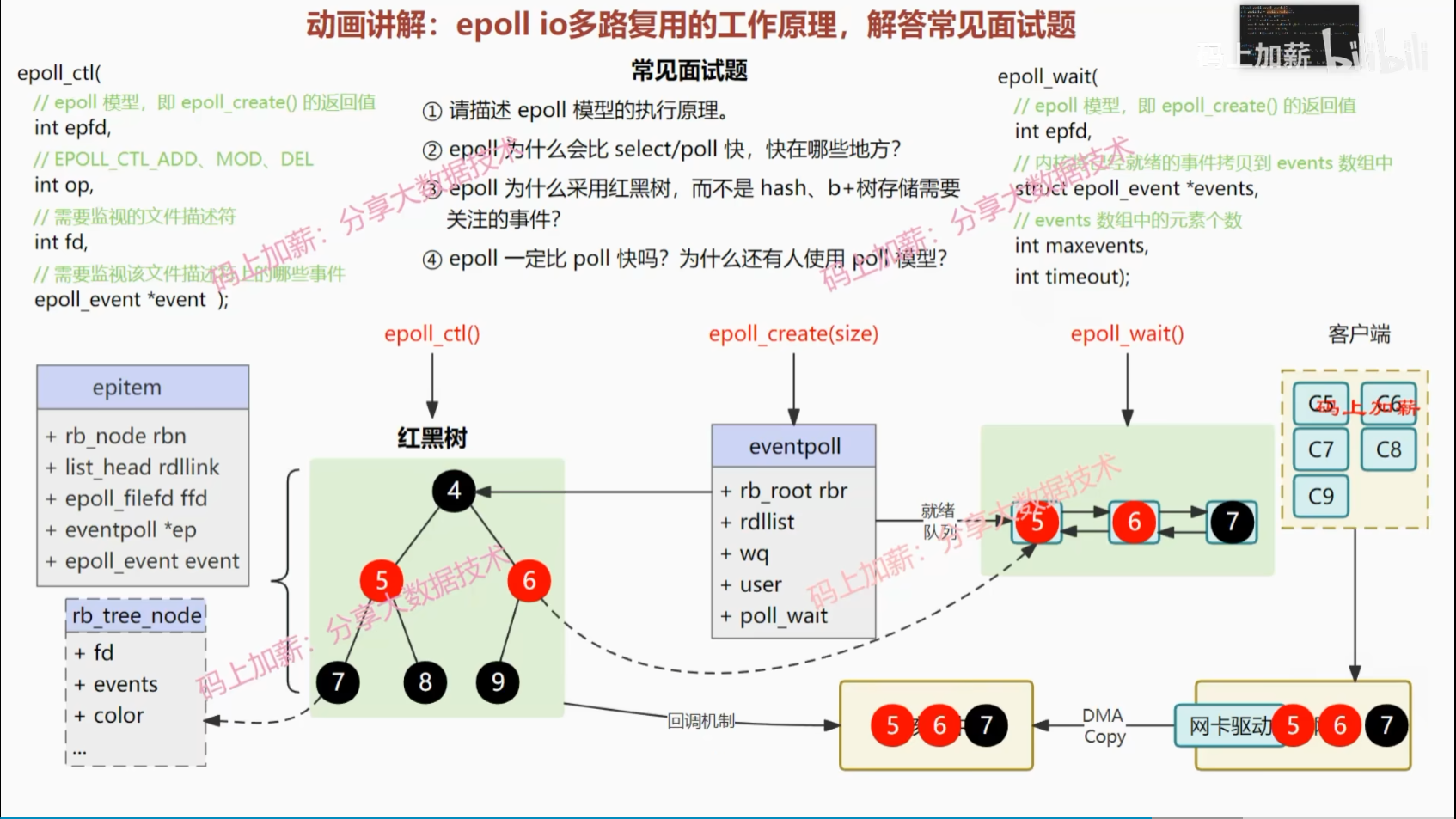
epoll面试重点
这些模型中,epoll 是面试的重点。常见问题:
epoll 的执行原理
- epoll_ctl():注册区,结构为红黑树
- epoll_wait():就绪队列,结构为双向链表
epoll 为什么比 select/poll 快
- epoll_ctl() 监听时才将用户态拷贝到内核态,而非每次拷贝
- epoll_wait() 读取时仅拷贝已就绪的,不会拷贝未就绪的
- 采用回调,而非轮询,检查是否有文件描述符就续的时间复杂度O(1)
epoll 为什么采样红黑树,而不是hash、b+树
hash时间快,但可能需要哈希的动态扩容,频繁动态扩容开销大
B+树能降低树高度,做磁盘索引好,但在内存中没那么适用。
- 磁盘IO:操作的时间消耗主要在寻道和旋转,降低寻址次数必要性更大
- 内存IO:寻址的成本几乎可以忽略不计,时间消耗主要在于数据的读取,主要目标是减少读取的数据量
并且,B+树非叶子节点并不存储数据信息,这对磁盘查询很高效。但对于可以直接存取地址的内存来说,这一点优势不大
epoll 一定比 poll 快吗,为什么还有人使用poll模型
- 未必,只有在高并发,epoll才全胜
触发机制
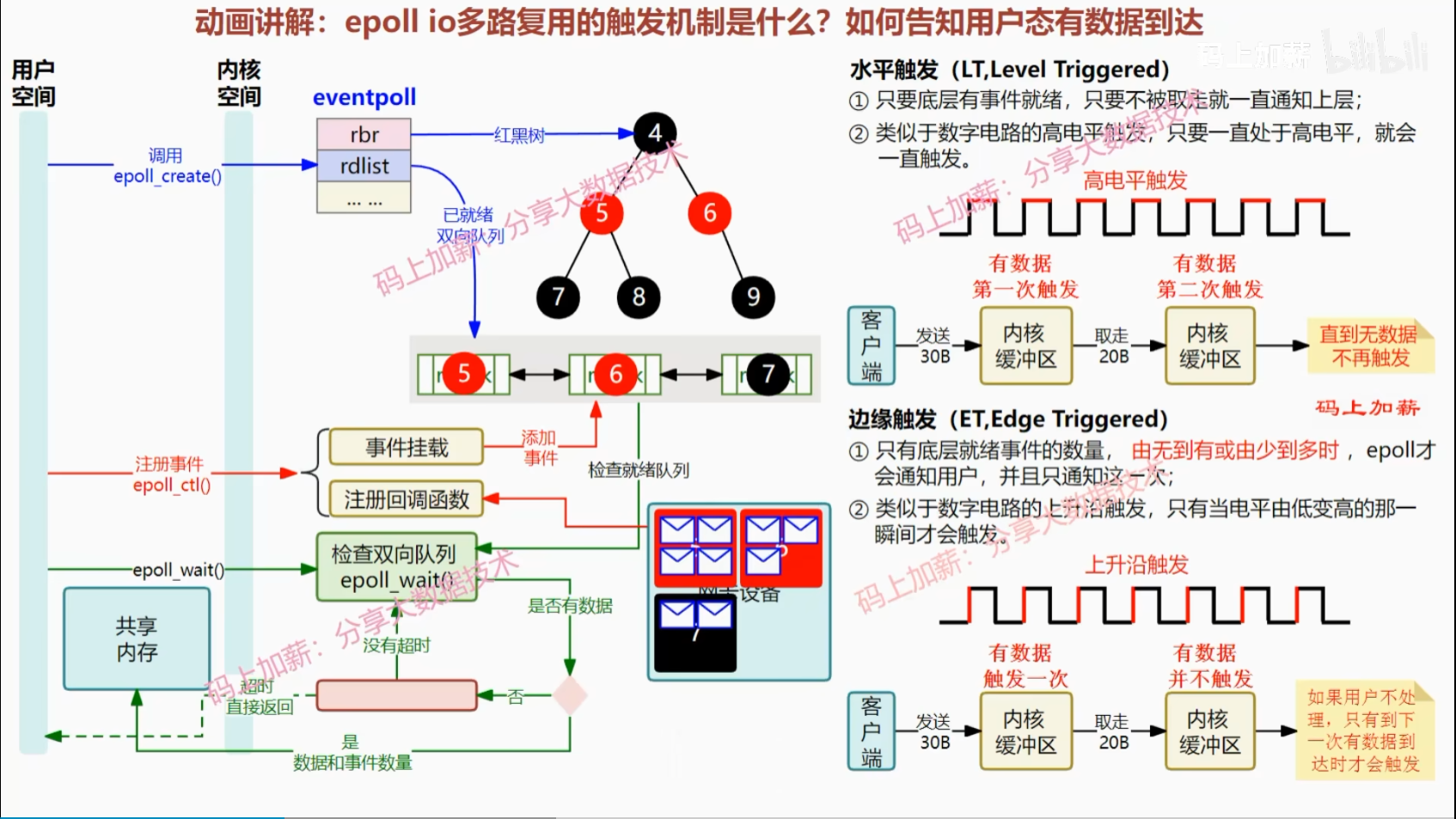
一般默认水平触发。边缘触发更复杂,但通知用户态的次数更少,Nginx采用这种