文件系统的结构
文件系统的结构
前面提到 Linux 是用位图的方式管理空闲空间。
- 创建新文件时分配inode:用户在创建一个新文件时,Linux 内核会通过 inode 的位图找到空闲可用的 inode,并进行分配
- 存储数据时分配块:要存储数据时,会通过块的位图找到空闲的块,并分配
大文件问题 —— 块组
先区分一下
- 逻辑块/块 (大小单位)
- 超级块:Size 1块,存全局信息
- 数据块:Size N块,(存文件内容?文件块?)
- 块组:见后
原方案
但仔细计算一下还是有问题的
数据块的位图是放在磁盘块里的,假设是放在一个块里,一个块 4K,每位表示一个数据块,共可以表示 4 * 1024 * 8 = 2^15 个空闲块,由于 1 个数据块是 4K 大小,那么最大可以表示的空间为 2^15 * 4 * 1024 = 2^27 个 byte,也就是 128M。
也就是说按照上面的结构,如果采用「一个块的位图 + 一系列的块」外加「一个块的 inode 的位图 + 一系列的 inode 的结构」能表示的最大空间也就 128M,这太少了,现在很多文件都比这个大。
块组方案
在 Linux 文件系统,把这个结构称为一个块组,那么有 N 多的块组,就能够表示 N 大的文件(哈?是N个块组还是块组里有N个数据块?表示的是N这么大还是N个大的文件)
下图给出了 Linux Ext2 整个文件系统的结构和块组的内容,文件系统都由大量块组组成,在硬盘上相继排布:
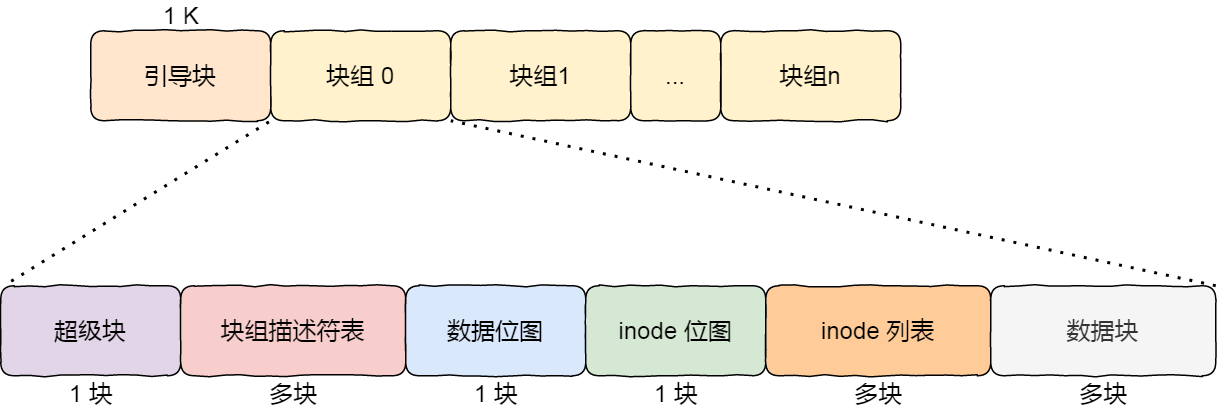
最前面的第一个块是引导块,在系统启动时用于启用引导,接着后面就是一个一个连续的块组了,块组的内容如下:
超级块(全局、重复),包含的是文件系统的重要信息,比如 inode 总个数、块总个数、每个块组的 inode 个数、每个块组的块个数等等。
这个可以通过命令
df -i和df -l查看$ df -i 文件系统 Inodes 已用I 可用I 已用I% 挂载点 tmpfs 2031005 1482 2029523 1% /run /dev/sda5 7749632 246137 7503495 4% / tmpfs 2031005 1 2031004 1% /dev/shm tmpfs 2031005 4 2031001 1% /run/lock /dev/sda2 0 0 0 - /boot/efi tmpfs 406201 159 406042 1% /run/user/1000 $ df -l 文件系统 1K的块 已用 可用 已用% 挂载点 tmpfs 1624804 2244 1622560 1% /run /dev/sda5 121451184 14523436 100712224 13% / tmpfs 8124020 0 8124020 0% /dev/shm tmpfs 5120 4 5116 1% /run/lock /dev/sda2 524252 6220 518032 2% /boot/efi tmpfs 1624804 120 1624684 1% /run/user/1000
块组描述符(全局、重复),包含文件系统中各个块组的状态,比如块组中空闲块和 inode 的数目等,每个块组都包含了文件系统中「所有块组的组描述符信息」。
数据位图和 inode 位图, 用于表示对应的数据块或 inode 是空闲的,还是被使用中。
inode 列表,包含了块组中所有的 inode,inode 用于保存文件系统中与各个文件和目录相关的所有元数据。
数据块,包含文件的有用数据。
重复信息(为什么重复、优化方案)
你可以会发现每个块组里有很多重复的信息,比如 超级块和块组描述符表,这两个都是全局信息,而且非常的重要,这么做是有两个原因:
- 如果系统崩溃破坏了超级块或块组描述符,有关文件系统结构和内容的所有信息都会丢失。如果有冗余的副本,该信息是可能恢复的。
- 通过使文件和管理数据尽可能接近,减少了磁头寻道和旋转,这可以提高文件系统的性能。
不过,Ext2 的后续版本采用了稀疏技术。该做法是,超级块和块组描述符表不再存储到文件系统的每个块组中,而是只写入到块组 0、块组 1 和其他 ID 可以表示为 3、 5、7 的幂的块组中。